1. Manual de Monitoramento do SPID¶
Esse manual descreve o ambiente do SPID, seu processo de inicialização, desligamento, monitoramento e demais recursos. O ambiente do SPID é composto por um conjunto de serviços server-side: SPID Server e Control Panel, GBDS, SQL Server e Ambari Services.
1.1. Monitoramento do Sistema¶
A Griaule recomenda ferramentas de monitoramento como Zabbix, Cacti e outros sistemas para automatizar o rastreamento de recursos e desempenho do sistema.
1.1.1. Status do SPID¶
Um dos meios de monitorar o SPID é através da API,
disponível pelo URL
http://<hostname>:8082/gbs-spid-server/service/cluster/ping
Note que na configuração padrão, o SPID é configurado na porta 8082.
Note
Esse teste pode ser feito por um browser.
Se o SPID estiver funcionando, a seguinte mensagem será exibida:
Pong!
1.1.1.1. Server-side¶
Há dois meios para fazer a verificação de status via terminal.
service spid status
ou
ps aux | grep spid-server | grep -v grep
A resposta para esses comandos deve exibir o processo em funcionamento.
1.1.2. Status do Painel de Controle do SPID¶
O Painel de Controle SPID é um serviço web e está disponível através do URL
http://<hostname>:58086/gbs-spid-controlpanel. Na configuração padrão, o
painel de contorle atua pela porta 58086.
1.1.2.1. Server-side¶
Há dois meios para fazer a verificação de status via terminal.
service spid-cp status
ou
ps aux | grep spid-controlpanel | grep -v grep
A resposta para esses comandos deve exibir o processo em funcionamento.
1.1.3. Idnservice Server-side¶
O IDN Service da Griaule é um serviço opcional, e, quando usado, pode ser checado pelos seguintes comandos:
service idnservice status
ou
ps aux | grep spid-idnservice | grep -v grep
A resposta para esses comandos deve exibir o processo em funcionamento.
1.1.4. Status do GBDS API¶
Um dos meios de monitorar a API do GBDS é através da URL
http://<hostname>:8085/gbds/v2/operations/ping.
Sempre aponte a URL para um nó GBDS que hospeda a API. Na configuração padrão, a API funciona na porta 8085. A API deve retornar a seguinte mensagem:
{"data":"pong!"}
Uma verificação extra, que testa também o acesso ao Banco de Dados, está disponível através do seguinte endereço:
http://<hostname>:8085/gbds/v2/exceptions/EndDate=1400000000000
Ao clicar no link, o API chegará exceções até a data 13 de Maio de 2014 (em epoch time), então, o API não deverá retornar mensagens de exceções. Se a resposta for similar a resposta abaixo, a conexão com o banco está funcionando.
{"pagination":{"total":0,"count":0,"pageSize":0,"currentPage":0,"totalPages":0}}
Note
Em vez de ping, pode-se fazer uma listagens de exceções no banco de dados, mas essa operação demanda mais recursos, então deve ser usada com restrições.
1.1.4.1. Server-side¶
O GBDS API é executado via um serviço nomeado gbdsapid. O seguinte comando pode
ser usado para checar se esse serviço está funcionando.
Important
Lembre-se de repetir o comando em cada nodo que a API estiver funcionando.
service gbsapid status
ou
ps aux | grep gbsapi | grep -v grep
A resposta para esses comandos deve exibir o processo em funcionamento da API.
1.1.5. Status do GBDS¶
1.1.5.1. Server-side¶
O GBDS é executado como um processo. Lembre-se de repetir o comando em cada nodo do cluster GBDS.
O primeiro comando pode ser usado para chegar se o processo do GBDS está sendo executado:
ps aux | grep -v grep | grep griaulebiometrics.gbds.driver.Driver
A saída desse comando deve ser exibido se o processo estiver funcionando.
O segundo comando pode ser usado para checar a contagem de matchers:
ps aux | grep akka | grep -v grep | wc -l
A saída desse comando exibirá a quantidade de matchers que estão sendo executados.
1.2. Solução de Problemas¶
1.2.1. GBDS¶
Em caso de problemas o GBDS deve ser reiniciado. Primeiro, é necessário checar o status do serviço e pará-lo.
su griaule
/var/lib/griaule/gbds/scripts/kill-cluster.sh
#Call again till all nodes return that no service is running
/var/lib/griaule/gbds/scripts/kill-cluster.sh
Então, como usuário griaule, o seguinte script deve ser executado para
iniciar o driver.
/var/lib/griaule/gbds/scripts/start-cluster.sh
Note
Mais detalhes para o GBDS podem ser encontrados nos logs.
1.2.2. GBDS API¶
Se houver algum problema com a API, ela deve ser reiniciada usando um
usuário griaule ou superuser.
service gbsapid restart #restart API
service gbsapid status #check api status
1.2.3. SPID¶
Se houver algum problema com o SPID, ele deve ser reiniciado usando um
usuário griaule ou superuser.
service spid restart #restart spid
service spid status #check spid status
1.2.4. SPID Control Panel¶
Se houver algum problema com o Contrl Panel, ele deve ser reiniciado usando um
usuário griaule ou superuser.
service spid-cp restart
service spid-cp status
1.2.5. IDN Service¶
Se houver algum problema com o indservice, ele deve ser reiniciado usando um
usuário griaule ou superuser.
Note
Lembre-se que o IDN da Griaule é opcional, os usuários podem optar por implementá-lo por si mesmos.
service idnservice restart
service idnservice status
1.2.6. Logs¶
Em caso de algum problema ser encontrado, o time de suporte deve ser contatado. Assim que o contato for feito, é importante enviar os logs relacionados ao problema para diminuir o tempo de correção.
Aplicação com erro |
Caminho para os logs |
|---|---|
HBase |
/var/log/hbase/ |
HDFS |
/var/log/hadoop/hdfs/hadoop-hdfs-datanode-hostname.log |
GBDS |
/var/log/griaule/gbds/gbds.log |
GBDS API (start up process) |
/var/log/griaule/gbsapi/console.out |
GBDS API |
/var/log/griaule/gbsapi/gbsapi.log |
SPID |
/var/log/griaule/spid/ac.log |
SPID Control Panel |
/var/log/griaule/spid/controlpanel.log |
idnService |
/var/log/griaule/idnservice/ |
1.3. Processos pós-reinicialização de Clusters¶
Se todos os nós do cluster forem reiniciados simultaneamente, os serviços Ambari deverão ser reiniciados manualmente. Este procedimento também pode ser usado no caso de o ambiente ficar offline como uma abordagem inicial para tratar o incidente.
1.3.1. Reinicialização de serviços Ambari¶
Para acessar o Painel de Controle do Ambari, acesse o URL http://<hostname>:8080 a
partir de um browser web e faça o login. Por padrão, tanto o login e a senha são admin.
Então, no painel lateral esquerdo, na aba Services, clique em ... e depois em Start All.
No fim da operação, todos os serviços devem estar em funcionamento (destacados pela bola na cor verde).
Se algum serviço falhar na inicialização, ele será marcado em vermelho e deverá ser iniciado manualmente.
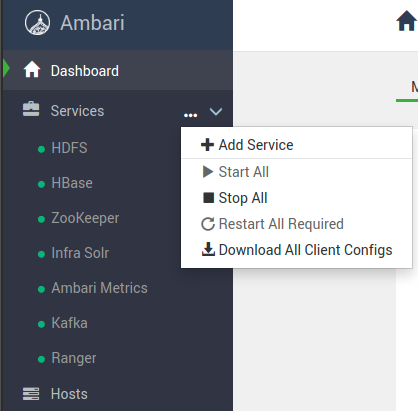
Note
No canto superior direito da tela você tem um ícone de engrenagem, pressionando o usuário pode acompanhar o status atual de inicialização.
Você deve verificar se o namenode não está sendo executado em Safemode por algum problema. Portanto, verifique o status o namenode.
hdfs dfsadmin -fs hdfs://<hostname>:8020 -safemode get | grep 'Safe mode is OFF'
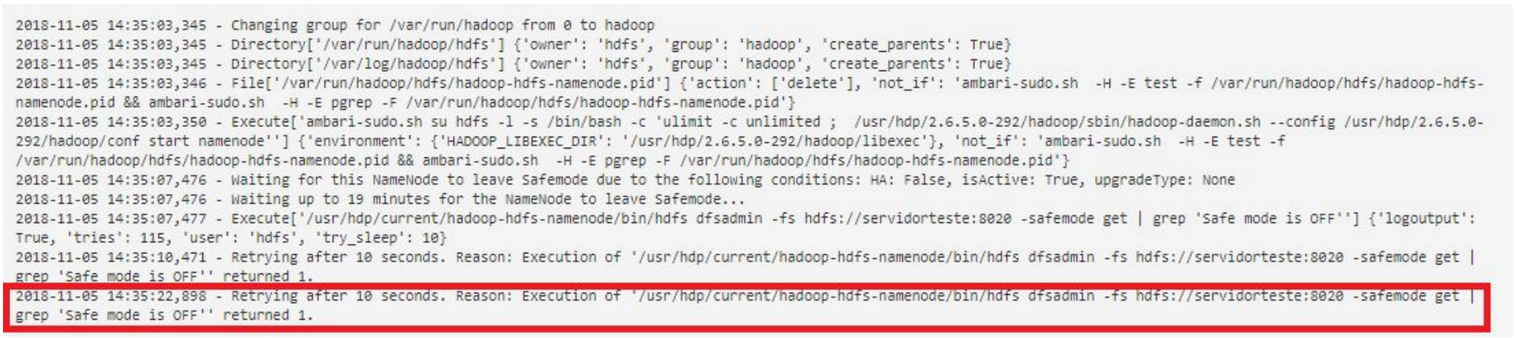
Se o namenode for iniciado em safemode, execute o seguinte comando no Nó 1 como um usuário hdfs.
sudo su - hdfs hdfs dfsadmin -safemode leave
1.3.2. Inicialização de serviços¶
Inicialize o GBDS, o GBDS API, o SPID Control Panel e o IDN Service como indicado em Solução de Problemas
1.3.2.1. Desligamento¶
O procedimento a seguir deve ser usado sempre que os servidores de produção forem desligados. Este procedimento também pode ser usado no caso do ambiente ficar offline como uma abordagem inicial para tratar o incidente.
Note
Você precisa de um superusuário para fazer as chamadas.
service spid stop
service spid-cp stop
service gbsapid stop
/var/lib/griaule/gbscluster/scripts/kill-gbscluster.sh
#Call again till all nodes return that no service is running
/var/lib/griaule/gbscluster/scripts/kill-gbscluster.sh
Acesse o Painel de Controle do Ambari via URL
http://<hostname>:8080.Pare todos os serviços do Hadoop clicando em
...em “Services” e então em “Stop All”.
1.4. Informações Adicionais¶
O GBDS é vinculado à CPU, o que significa que sempre usará o máximo de CPU possível para executar suas operações. Por isso, é comum que o software de monitoramento aponte alto uso da CPU nos nós do cluster.